8.7 KiB
WiseFlow
Wiseflow is an agile information mining tool that extracts concise messages from various sources such as websites, WeChat official accounts, social platforms, etc. It automatically categorizes and uploads them to the database.
We are not short of information; what we need is to filter out the noise from the vast amount of information so that valuable information stands out!
See how WiseFlow helps you save time, filter out irrelevant information, and organize key points of interest!
https://github.com/TeamWiseFlow/wiseflow/assets/96130569/bd4b2091-c02d-4457-9ec6-c072d8ddfb16
🔥 Major Update V0.3.0
-
✅ Completely rewritten general web content parser, using a combination of statistical learning (relying on the open-source project GNE) and LLM, adapted to over 90% of news pages;
-
✅ Brand new asynchronous task architecture;
-
✅ New information extraction and labeling strategy, more accurate, more refined, and can perform tasks perfectly with only a 9B LLM!
🌟 Key Features
-
🚀 Native LLM Application
We carefully selected the most suitable 7B~9B open-source models to minimize usage costs and allow data-sensitive users to switch to local deployment at any time. -
🌱 Lightweight Design
Without using any vector models, the system has minimal overhead and does not require a GPU, making it suitable for any hardware environment. -
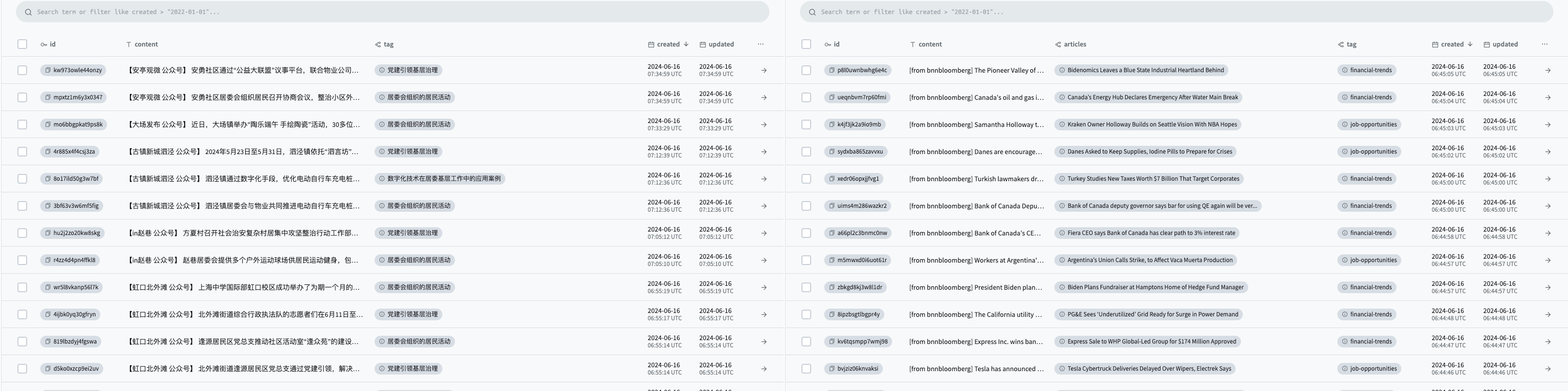
🗃️ Intelligent Information Extraction and Classification
Automatically extracts information from various sources and tags and classifies it according to user interests.😄 Wiseflow is particularly good at extracting information from WeChat official account articles; for this, we have configured a dedicated mp article parser!
-
🌍 Can be Integrated into Any RAG Project
Can serve as a dynamic knowledge base for any RAG project, without needing to understand the code of Wiseflow, just operate through database reads! -
📦 Popular Pocketbase Database
The database and interface use PocketBase. Besides the web interface, APIs for Go/Javascript/Python languages are available.
🔄 What are the Differences and Connections between Wiseflow and Common Crawlers, RAG Projects?
| Feature | Wiseflow | Crawler / Scraper | RAG Projects |
|---|---|---|---|
| Main Problem Solved | Data processing (filtering, extraction, labeling) | Raw data acquisition | Downstream applications |
| Connection | Can be integrated into Wiseflow for more powerful raw data acquisition | Can integrate Wiseflow as a dynamic knowledge base |
📥 Installation and Usage
WiseFlow has virtually no hardware requirements, with minimal system overhead, and does not need a discrete GPU or CUDA (when using online LLM services).
-
Clone the Code Repository
😄 Liking and forking is a good habit
git clone https://github.com/TeamWiseFlow/wiseflow.git cd wiseflow -
Configuration
Copy
env_samplein the directory and rename it to.env, then fill in your configuration information (such as LLM service tokens) as follows:- LLM_API_KEY # API key for large model inference service (if using OpenAI service, you can omit this by deleting this entry)
- LLM_API_BASE # Base URL for the OpenAI-compatible model service (omit this if using OpenAI service)
- WS_LOG="verbose" # Enable debug logging, delete if not needed
- GET_INFO_MODEL # Model for information extraction and tagging tasks, default is gpt-3.5-turbo
- REWRITE_MODEL # Model for near-duplicate information merging and rewriting tasks, default is gpt-3.5-turbo
- HTML_PARSE_MODEL # Web page parsing model (smartly enabled when GNE algorithm performs poorly), default is gpt-3.5-turbo
- PROJECT_DIR # Location for storing cache and log files, relative to the code repository; default is the code repository itself if not specified
- PB_API_AUTH='email|password' # Admin email and password for the pb database (use a valid email for the first use, it can be a fictitious one but must be an email)
- PB_API_BASE # Not required for normal use, only needed if not using the default local PocketBase interface (port 8090)
-
Model Recommendation
After extensive testing (in both Chinese and English tasks), for comprehensive effect and cost, we recommend the following for GET_INFO_MODEL, REWRITE_MODEL, and HTML_PARSE_MODEL: "zhipuai/glm4-9B-chat", "alibaba/Qwen2-7B-Instruct", "alibaba/Qwen2-7B-Instruct".
These models fit the project well, with stable command adherence and excellent generation effects. The related prompts for this project are also optimized for these three models. (HTML_PARSE_MODEL can also use "01-ai/Yi-1.5-9B-Chat", which also performs excellently in tests)
⚠️ We strongly recommend using SiliconFlow's online inference service for lower costs, faster speeds, and higher free quotas! ⚠️
SiliconFlow online inference service is compatible with the OpenAI SDK and provides open-source services for the above three models. Just configure LLM_API_BASE as "https://api.siliconflow.cn/v1" and set up LLM_API_KEY to use it.
-
Local Deployment
As you can see, this project uses 7B/9B LLMs and does not require any vector models, which means you can fully deploy this project locally with just an RTX 3090 (24GB VRAM).
Ensure your local LLM service is compatible with the OpenAI SDK, and configure LLM_API_BASE accordingly.
-
Run the Program
For regular users, it is strongly recommended to use Docker to run the Chief Intelligence Officer.
📚 For developers, see /core/README.md for more.
Access data obtained via PocketBase:
- http://127.0.0.1:8090/_/ - Admin dashboard UI
- http://127.0.0.1:8090/api/ - REST API
- https://pocketbase.io/docs/ check more
-
Adding Scheduled Source Scanning
After starting the program, open the PocketBase Admin dashboard UI (http://127.0.0.1:8090/_/)
Open the sites form.
Through this form, you can specify custom sources, and the system will start background tasks to scan, parse, and analyze the sources locally.
Description of the sites fields:
- url: The URL of the source. The source does not need to specify the specific article page, just the article list page. Wiseflow client includes two general page parsers that can effectively acquire and parse over 90% of news-type static web pages.
- per_hours: Scanning frequency, in hours, integer type (range 1~24; we recommend a scanning frequency of no more than once per day, i.e., set to 24).
- activated: Whether to activate. If turned off, the source will be ignored; it can be turned on again later. Turning on and off does not require restarting the Docker container and will be updated at the next scheduled task.
🛡️ License
This project is open-source under the Apache 2.0 license.
For commercial use and customization cooperation, please contact Email: 35252986@qq.com.
- Commercial customers, please register with us. The product promises to be free forever.
- For customized customers, we provide the following services according to your sources and business needs:
- Custom proprietary parsers
- Customized information extraction and classification strategies
- Targeted LLM recommendations or even fine-tuning services
- Private deployment services
- UI interface customization
📬 Contact Information
If you have any questions or suggestions, feel free to contact us through issue.
🤝 This Project is Based on the Following Excellent Open-source Projects:
- GeneralNewsExtractor (General Extractor of News Web Page Body Based on Statistical Learning) https://github.com/GeneralNewsExtractor/GeneralNewsExtractor
- json_repair (Repair invalid JSON documents) https://github.com/josdejong/jsonrepair/tree/main
- python-pocketbase (PocketBase client SDK for Python) https://github.com/vaphes/pocketbase
Citation
If you refer to or cite part or all of this project in related work, please indicate the following information:
Author: Wiseflow Team
https://openi.pcl.ac.cn/wiseflow/wiseflow
https://github.com/TeamWiseFlow/wiseflow
Licensed under Apache2.0