mirror of
https://github.com/yihong0618/Kindle_download_helper.git
synced 2025-11-22 07:59:04 +08:00
267 lines
11 KiB
Markdown
267 lines
11 KiB
Markdown
# Kindle_download_helper
|
||
|
||
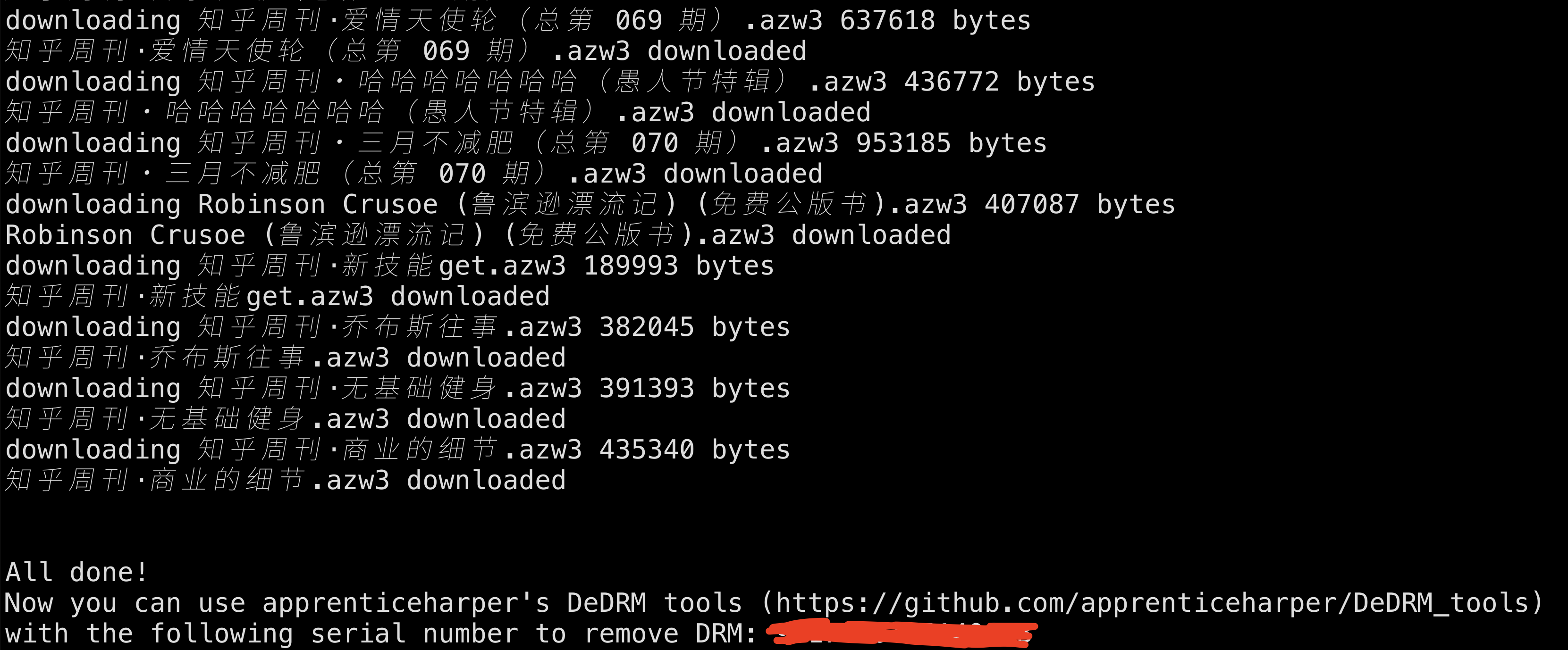
Download all your kindle books script.
|
||
|
||
|
||
|
||
## **2024.01 Amazon has shut down the China storefront homepage. You can download your books by visiting this link: https://www.amazon.cn/hz/mycd/myx#/home/content/booksAll/dateDsc/**
|
||
|
||
## 2023.06.26 If you don't have a physical Kindle device, you can use the following command. The downloaded EPUB files will be placed in the EPUB folder.
|
||
|
||
If you encounter the error `AttributeError: 'NoneType' object has no attribute 'url'`, please refer to:
|
||
https://github.com/yihong0618/Kindle_download_helper/issues/155#issuecomment-1928677849
|
||
```console
|
||
pip3 install -r requirements.txt
|
||
python no_kindle.py -e ${email} -p ${password}
|
||
|
||
# To download push books
|
||
python no_kindle.py -e ${email} -p ${password} --pdoc
|
||
|
||
# !!!!!! Amazon has taken down the China web storefront.
|
||
# You can generate the purchase records and notes of all your e-books for data analysis
|
||
python no_kindle.py -e ${email} -p ${password} --memory
|
||
|
||
# Supports exporting all bookmarks and reading information (Clipping data) #153
|
||
python no_kindle.py -e ${email} -p ${password} --bookmark
|
||
```
|
||
|
||
## Installing Kindle_download_helper
|
||
|
||
### GUI Application Download
|
||
|
||
Go to the [Release](https://github.com/yihong0618/Kindle_download_helper/releases) page, download the binary file for your system and extract it.
|
||
|
||
### Help
|
||
|
||
- If you encounter issues opening the binary, please refer to [#25](https://github.com/yihong0618/Kindle_download_helper/issues/25)
|
||
- For Kindle download issues (triggered by Amazon risk control), see [#69](https://github.com/yihong0618/Kindle_download_helper/issues/69)
|
||
- Mac beginner's guide by @chongiscool, see [#76](https://github.com/yihong0618/Kindle_download_helper/issues/76)
|
||
|
||
### CLI Installation and Usage
|
||
|
||
1. python3
|
||
2. requirements
|
||
|
||
```python
|
||
python3 --version # check python version
|
||
```
|
||
|
||
```python
|
||
pip3 install kindle_download # install via pip
|
||
```
|
||
|
||
```bash
|
||
git clone https://github.com/yihong0618/Kindle_download_helper.git && cd Kindle_download_helper
|
||
```
|
||
|
||
```python
|
||
pip3 install -r requirements.txt
|
||
```
|
||
|
||
```python
|
||
python kindle.py -h # view usage parameters
|
||
|
||
usage: kindle.py [-h] [--cookie COOKIE | --cookie-file COOKIE_FILE] [--cn] [--jp] [--de] [--uk] [--resume-from INDEX] [--cut-length CUT_LENGTH] [-o OUTDIR] [-od OUTDEDRMDIR] [-s SESSION_FILE] [--pdoc]
|
||
[--resolve_duplicate_names] [--readme] [--dedrm] [--list] [--device_sn DEVICE_SN] [--mode MODE]
|
||
[csrf_token]
|
||
|
||
positional arguments:
|
||
csrf_token amazon or amazon cn csrf token
|
||
|
||
optional arguments:
|
||
-h, --help show this help message and exit
|
||
--cookie COOKIE amazon or amazon cn cookie
|
||
--cookie-file COOKIE_FILE
|
||
load cookie local file
|
||
--cn if your account is an amazon.cn account
|
||
--jp if your account is an amazon.co.jp account
|
||
--de if your account is an amazon.de account
|
||
--uk if your account is an amazon.co.uk account
|
||
--resume-from INDEX resume from the index if download failed
|
||
--cut-length CUT_LENGTH
|
||
truncate the file name
|
||
-o OUTDIR, --outdir OUTDIR
|
||
download output dir
|
||
-od OUTDEDRMDIR, --outdedrmdir OUTDEDRMDIR
|
||
download output dedrm dir
|
||
-s SESSION_FILE, --session-file SESSION_FILE
|
||
The reusable session dump file
|
||
--pdoc to download personal documents or ebook
|
||
--resolve_duplicate_names
|
||
Resolve duplicate names files to download
|
||
--readme If you want to generate kindle readme stats
|
||
--dedrm If you want to `dedrm` directly
|
||
--list just list books/pdoc, not to download
|
||
--device_sn DEVICE_SN
|
||
Download file for device with this serial number
|
||
--mode MODE Mode of download, all : download all files at once, sel: download selected files
|
||
```
|
||
|
||
### Downloading Kindle Books
|
||
|
||
Try to [automatically retrieve cookie](#automatic-cookie) and csrfToken for download
|
||
|
||
```python
|
||
python3 kindle.py --dedrm --cn ## --dedrm to remove DRM
|
||
```
|
||
|
||
(Recommended) [Manually enter cookie](#retrieving-cookie) and csrfToken for download
|
||
|
||
```python
|
||
python3 kindle.py ${csrfToken} --cookie ${cookie} --dedrm --cn # Download China-market books and remove DRM
|
||
python3 kindle.py ${csrfToken} --cookie ${cookie} --dedrm # Download US-market books
|
||
```
|
||
|
||
By default, all files are downloaded. To manually select which books to download, execute:
|
||
|
||
```python
|
||
python3 kindle.py --mode sel # or "python3 kindle.py --pdoc --mode sel" for personal documents
|
||
```
|
||
|
||
After retrieving the book list, the program will prompt:
|
||
|
||
``` string
|
||
Input the index of books you want to download, split by space (q to quit, l to list books).
|
||
```
|
||
|
||
To quit, type "q" and press Enter; type "l" and press Enter to re-display the book list.
|
||
To download books, input the corresponding indices (e.g., 7 10 20):
|
||
|
||
``` string
|
||
7 10 20
|
||
```
|
||
|
||
Indices can also be specified with ranges, for example:
|
||
|
||
``` string
|
||
4 5 10:12 15
|
||
```
|
||
|
||
This downloads books 4, 5, 10, 11, 12, and 15.
|
||
|
||
### Retrieving Cookie
|
||
|
||
If the cookie is reported as invalid by default, you can manually input it.
|
||
On the [all books](https://www.amazon.cn/hz/mycd/myx#/home/content/booksAll/dateDsc/) page, open the browser's developer tools (F12), go to the Network panel, locate any `ajax` request, and copy the `Cookie` from its request headers. The csrfToken can also be found in the Payload.
|
||
|
||
Then run:
|
||
|
||
```python
|
||
python3 kindle.py --cn --cookie ${cookie}
|
||
```
|
||
|
||
You can also save the cookie to a text file and run `python3 kindle.py --cookie-file ${cookie_file}` to download books.
|
||
|
||
### Retrieving CSRF Token
|
||
|
||
If the process fails to obtain the CSRF token, you can manually input it.
|
||
The csrfToken can be found in the page source on the [all books](https://www.amazon.cn/hz/mycd/myx#/home/content/booksAll/dateDsc/) page. Right-click, view the page source, and search for `csrfToken` to copy its value. Then run:
|
||
|
||
```python
|
||
# CSRF Token
|
||
python3 kindle.py --cn ${csrfToken}
|
||
# Both cookie and CSRF Token
|
||
python3 kindle.py --cn --cookie ${cookie} ${csrfToken}
|
||
```
|
||
|
||
## Automatically Retrieving Cookie
|
||
|
||
If you are running on your local machine, the project can use the [browser-cookie3](https://github.com/borisbabic/browser_cookie3) library to automatically retrieve cookies from your browser.
|
||
|
||
### Using `amazon.cn`
|
||
|
||
1. Log in to amazon.cn
|
||
2. Visit <https://www.amazon.cn/hz/mycd/myx#/home/content/booksAll/dateDsc/>
|
||
3. Right-click the page source and search for `csrfToken`, then copy its value
|
||
4. Run `python3 kindle.py --cn`
|
||
5. To download push files, run `python3 kindle.py --cn --pdoc`
|
||
6. To directly perform DRM removal (may not always work), run `python3 kindle.py --cn --pdoc --dedrm`
|
||
|
||
### How to use `amazon.com`
|
||
|
||
1. Log in to amazon.com
|
||
2. Visit <https://www.amazon.com/hz/mycd/myx#/home/content/booksAll/dateDsc/>
|
||
3. Right-click the page source, find the `csrfToken` and copy its value
|
||
4. Run: `python3 kindle.py`
|
||
5. For document files, run: `python3 kindle.py --pdoc`
|
||
|
||
### How to use `amazon.de`
|
||
|
||
1. Log in to amazon.de
|
||
2. Visit <https://www.amazon.de/hz/mycd/myx#/home/content/booksAll/dateDsc/>
|
||
3. Right-click the page source, find the `csrfToken` and copy its value
|
||
4. Run: `python3 kindle.py --de`
|
||
5. For document files, run: `python3 kindle.py --de --pdoc`
|
||
|
||
### How to use `amazon.co.uk`
|
||
|
||
1. Log in to amazon.co.uk
|
||
2. Visit <https://www.amazon.co.uk/hz/mycd/myx#/home/content/booksAll/dateDsc/>
|
||
3. Right-click the page source, find the `csrfToken` and copy its value
|
||
4. Run: `python3 kindle.py --uk`
|
||
5. For document files, run: `python3 kindle.py --uk --pdoc`
|
||
|
||
### Using `amazon.jp`
|
||
|
||
1. Log in to amazon.co.jp
|
||
2. Visit <https://www.amazon.co.jp/hz/mycd/myx#/home/content/booksAll/dateDsc/>
|
||
3. Right-click the page source, search for `csrfToken`, and copy its value
|
||
4. Run: `python3 kindle.py --jp`
|
||
5. To download push files, run: `python3 kindle.py --jp --pdoc`
|
||
|
||
## Notes
|
||
|
||
- Cookie and CSRF token will expire; simply refresh the Amazon page.
|
||
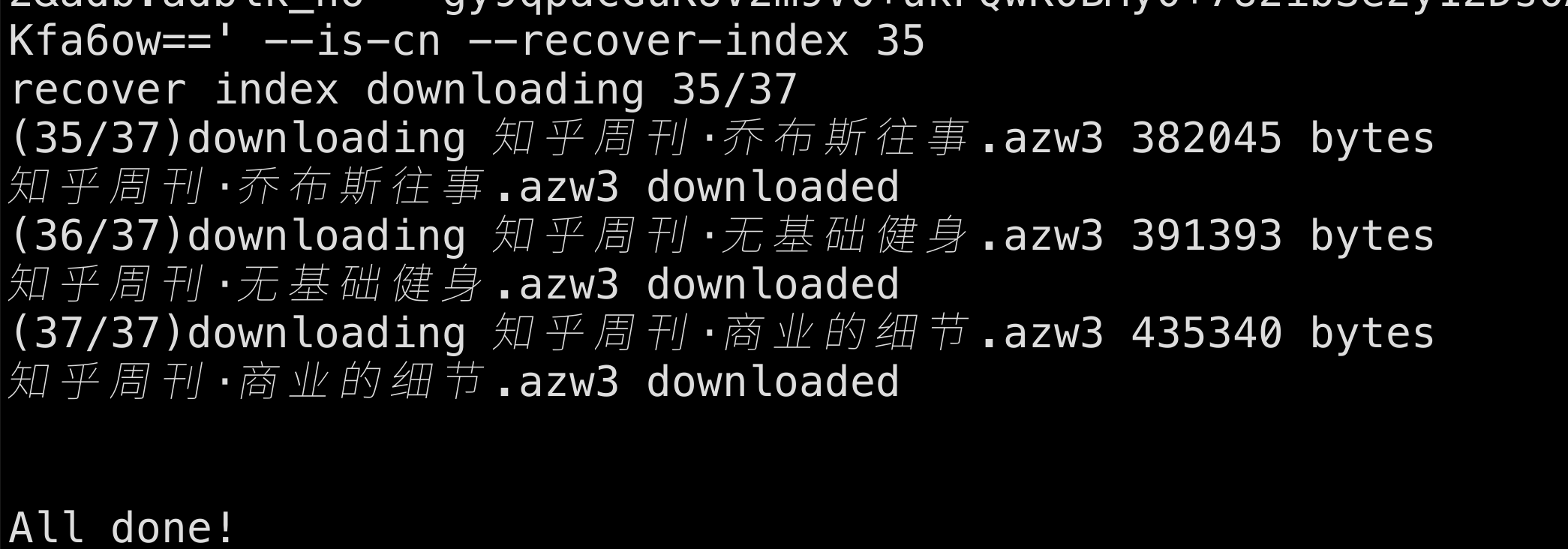
- The program will automatically create a `DOWNLOADS` directory in the current working directory; downloaded books will be stored there.
|
||
- Supports directly dedrm-ing mobi files with `--dedrm`; processed files are saved in the `DEDRMS` folder.
|
||
- If you use [DeDRM_tools](https://github.com/apprenticeharper/DeDRM_tools) to decrypt, the key is stored in key.txt.
|
||
- Alternatively, you can simply drag the file into Calibre (please google it).
|
||
- If the process fails, you can use e.g. `--resume-from ${num}`
|
||
- If a file name is too long, add `--cut-length 70` to truncate it.
|
||
- Supports downloading push files with `--pdoc`.
|
||
- If there are many duplicate pdoc or book names, you can use `--resolve_duplicate_names` to resolve conflicts.
|
||
- Error logs are recorded in .error_books.log.
|
||
- Supports generating a README of recently finished books with `--readme`; the file is generated as `my_kindle_stats.md`.
|
||
- Supports dedrm-ing mobi files directly using `--dedrm`; the output files are placed in `DEDRMS`.
|
||
- The script `dedrm.py` is used to decrypt downloaded e-book files independently, outputting both azw and epub formats by default.
|
||
|
||
```
|
||
# For the latter three parameters, only specify if necessary. Usage: python3 dedrm.py <source_directory> <target_directory> <key> <output_format>
|
||
# For example, to decrypt files in the "ebook" directory and generate dedrm files in epub format only:
|
||
$ python3 dedrm.py ebook DeDRMed "key_string_from_key.txt" epub
|
||
```
|
||
|
||
## Note
|
||
|
||
- The cookie and csrf token will expire; just refresh the Amazon page.
|
||
- The program automatically creates a `DOWNLOADS` directory in the working directory. Books are downloaded there.
|
||
- If you use [DeDRM_tools](https://github.com/apprenticeharper/DeDRM_tools) for decryption, the key is stored in key.txt.
|
||
- Alternatively, just drop the file into Calibre—please google it.
|
||
- If the process fails, you can use e.g. `--resume-from ${num}`
|
||
- If file names are too long, add `--cut-length 70` to truncate them.
|
||
- Supports downloading push files with `--pdoc`
|
||
- Use `--resolve_duplicate_names` to resolve conflicts with duplicate names.
|
||
- Error logs are saved in .error_books.log.
|
||
- Supports generating a README for recently finished books via `--readme`, which outputs to `my_kindle_stats.md`
|
||
|
||
|
||
|
||
## Contributions
|
||
|
||
1. Any issue or PR is welcome.
|
||
2. Run `black kindle.py kindle_gui.py`
|
||
|
||
## Acknowledgements
|
||
|
||
- @[Kindle](https://zh.m.wikipedia.org/zh/Kindle)
|
||
- @[DeDRM_tools](https://github.com/apprenticeharper/DeDRM_tools)
|
||
- @[frostming](https://github.com/frostming) – GUI and many contributions
|
||
- @[bladewang](https://github.com/bladewang) – PDOC download
|
||
- @[athrowaway2021](https://github.com/athrowaway2021/comix) – No need to have a real Kindle
|
||
|
||
## Appreciation
|
||
|
||
Thank you is enough
|
||
|
||
## Enjoy
|