* issues repair * improve mp_alblum for #55 * prompt engineering for get info * update to V0.3.1 * update to V0.3.1 |
||
|---|---|---|
| asset | ||
| core | ||
| dashboard | ||
| .dockerignore | ||
| .gitignore | ||
| compose.yaml | ||
| Dockerfile | ||
| env_sample | ||
| LICENSE | ||
| README_EN.md | ||
| README_JP.md | ||
| README_KR.md | ||
| README.md | ||
| version | ||
Chief Intelligence Officer (Wiseflow)
🚀 Chief Intelligence Officer (Wiseflow) is an agile information mining tool that can extract information from various sources such as websites, WeChat official accounts, social platforms, etc., based on set focus points, automatically categorize with labels, and upload to a database.
What we lack is not information, but the ability to filter out noise from the vast amount of information to reveal valuable information.
🌱 See how Chief Intelligence Officer helps you save time, filter out irrelevant information, and organize key points of interest! 🌱
- ✅ Universal web content parser, comprehensively using statistical learning (dependent on the open-source project GNE) and LLM, suitable for over 90% of news pages; (Wiseflow excels in extracting information from WeChat official account articles, for which we have configured a dedicated mp article parser!)
- ✅ Asynchronous task architecture;
- ✅ Information extraction and label classification using LLM (only requires an LLM of 9B size to perfectly execute tasks)!
https://github.com/TeamWiseFlow/wiseflow/assets/96130569/bd4b2091-c02d-4457-9ec6-c072d8ddfb16
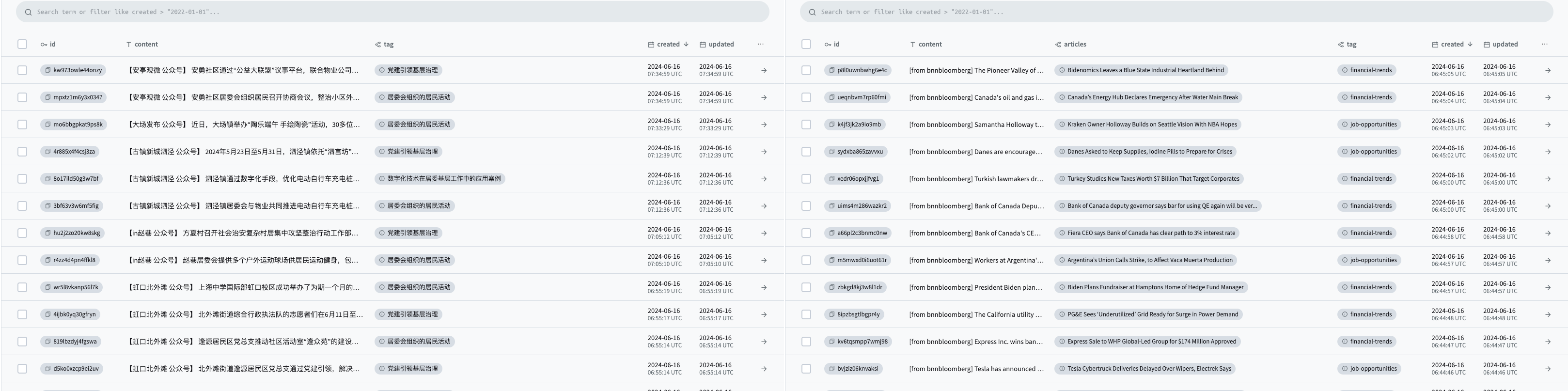
🔥 V0.3.1 Update
👏 Although some 9B-sized LLMs (THUDM/glm-4-9b-chat) can already achieve stable information extraction output, we found that for complex meaning tags (like "Party Building") or tags that require specific collection (like only collecting "community activities" without including large events like concerts), the current prompts cannot perform accurate extraction. Therefore, in this version, we have added an explanation field for each tag, which allows for clearer tag specification through input.
Note: Complex explanations require a larger model to understand accurately, see [Model Recommendations 2024-09-03](###-4. Model Recommendations [2024-09-03])
👏 Additionally, addressing the issue of prompt language selection in the previous version (which does not affect the output results), we have further simplified the solution in the current version. Users no longer need to specify the system language (which is not so intuitive in Docker), the system will determine the language of the prompt (and thus the output language of the info) based on the tag and its explanation, further simplifying the deployment and use of wiseflow. However, currently wiseflow only supports Simplified Chinese and English, other language needs can be achieved by changing the prompt in core/insights/get_info.py
🌹 Also, this update merges PRs from the past two months, with the following new contributors:
@wwz223 @madizm @GuanYixuan @xnp2020 @JimmyMa99
🌹 Thank you all for your contributions!
🌟 How to Integrate wiseflow into Your Application
wiseflow is a native LLM application, requiring only a 7B~9B size LLM to perform information mining, filtering, and classification tasks well, and does not require a vector model, making it suitable for various hardware environments for local and private deployment.
wiseflow stores the mined information in its built-in Pocketbase database, meaning integration does not require in-depth understanding of wiseflow's code, just read operations on the database!
PocketBase, as a popular lightweight database, currently has SDKs for Go/Javascript/Python languages.
- Go : https://pocketbase.io/docs/go-overview/
- Javascript : https://pocketbase.io/docs/js-overview/
- python : https://github.com/vaphes/pocketbase
🔄 How is wiseflow Different and Related to Common Crawler Tools and LLM-Agent Projects?
| Characteristic | Chief Intelligence Officer (Wiseflow) | Crawler / Scraper | LLM-Agent |
|---|---|---|---|
| Main Problem Solved | Data Processing (Filtering, Refining, Tagging) | Raw Data Acquisition | Downstream Applications |
| Relation | Can be integrated into WiseFlow, giving wiseflow stronger raw data acquisition capabilities | Can integrate WiseFlow as a dynamic knowledge base |
📥 Installation and Usage
1. Clone the Repository
🌹 Starring and forking are good habits 🌹
git clone https://github.com/TeamWiseFlow/wiseflow.git
cd wiseflow
2. Recommended to Run Using Docker
docker compose up
Note:
- Run the above command in the root directory of the wiseflow code repository;
- Create and edit the .env file before running, place it in the same directory as the Dockerfile (root directory of the wiseflow code repository), the .env file can refer to env_sample;
- The first time you run the docker container, you may encounter an error, which is normal because you have not yet created an admin account for the pb repository.
At this point, keep the container running, open your browser to http://127.0.0.1:8090/_/, and follow the prompts to create an admin account (must use an email), then fill in the created admin email (again, must be an email) and password into the .env file, and restart the container.
If you want to change the container's timezone and language, run the image with the following command
docker run -e LANG=zh_CN.UTF-8 -e LC_CTYPE=zh_CN.UTF-8 your_image
2. [Alternative] Run Directly Using Python
conda create -n wiseflow python=3.10
conda activate wiseflow
cd core
pip install -r requirements.txt
Then refer to the scripts in core/scripts to start pb, task, and backend separately (move the script files to the core directory)
Note:
- Be sure to start pb first, task and backend are independent processes, the order of startup does not matter, you can also start only one of them as needed;
- Download the pocketbase client for your device from https://pocketbase.io/docs/ and place it in the /core/pb directory;
- For pb runtime issues (including first-time run errors), refer to core/pb/README.md;
- Create and edit the .env file before use, place it in the root directory of the wiseflow code repository (parent directory of the core directory), the .env file can refer to env_sample, detailed configuration instructions below;
📚 For developers, see /core/README.md for more
Access data through pocketbase:
http://127.0.0.1:8090/_/ - Admin dashboard UI
http://127.0.0.1:8090/api/ - REST API
3. Configuration
Copy the env_sample in the directory and rename it to .env, fill in your configuration information (such as LLM service token) as follows:
Windows users who choose to run the python program directly can set the following items in "Start - Settings - System - About - Advanced System Settings - Environment Variables", and restart the terminal to take effect
-
LLM_API_KEY # API KEY for large model inference service
-
LLM_API_BASE # This project relies on the openai sdk, as long as the model service supports the openai interface, it can be used normally by configuring this item, if using openai service, delete this item
-
WS_LOG="verbose" # Set whether to start debug observation, if not needed, delete it
-
GET_INFO_MODEL # Model for information extraction and label matching tasks, default is gpt-4o-mini-2024-07-18
-
REWRITE_MODEL # Model for merging and rewriting similar information tasks, default is gpt-4o-mini-2024-07-18
-
HTML_PARSE_MODEL # Web page parsing model (smart enabled when GNE algorithm is not effective), default is gpt-4o-mini-2024-07-18
-
PROJECT_DIR # Location for storing data, cache, and log files, relative path to the code repository, default is the code repository if not filled
-
PB_API_AUTH='email|password' # Email and password for pb database admin (note that it must be an email, can be a fictional email)
-
PB_API_BASE # This item is not needed for normal use, only when you do not use the default pocketbase local interface (8090)
4. Model Recommendations [2024-09-03]
After repeated testing (Chinese and English tasks), the minimum usable models for GET_INFO_MODEL, REWRITE_MODEL, and HTML_PARSE_MODEL are: "THUDM/glm-4-9b-chat", "Qwen/Qwen2-7B-Instruct", and "Qwen/Qwen2-7B-Instruct"
Currently, SiliconFlow has officially announced that the Qwen2-7B-Instruct and glm-4-9b-chat online inference services are free, which means you can use wiseflow "at zero cost"!
😄 If you are willing, you can use my siliconflow invitation link, so I can also get more token rewards 😄
⚠️ V0.3.1 Update
If you use complex tags with explanations, the glm-4-9b-chat model size cannot guarantee accurate understanding. The models that have been tested to perform well for this type of task are Qwen/Qwen2-72B-Instruct and gpt-4o-mini-2024-07-18.
5. Adding Focus Points and Scheduled Scanning of Sources
After starting the program, open the pocketbase Admin dashboard UI (http://127.0.0.1:8090/_/)
5.1 Open the tags Form
Through this form, you can specify your focus points, and the LLM will refine, filter, and categorize information accordingly.
tags Field Explanation:
-
name, Focus point name
-
explaination, Detailed explanation or specific agreement of the focus point, such as "Only official information released by Shanghai regarding junior high school enrollment" (tag name is Shanghai Junior High School Enrollment Information)
-
activated, Whether to activate. If turned off, this focus point will be ignored, and can be turned back on later. Activating and deactivating does not require restarting the Docker container, it will update at the next scheduled task.
5.2 Open the sites Form
Through this form, you can specify custom sources, the system will start background scheduled tasks to perform source scanning, parsing, and analysis locally.
sites Field Explanation:
-
url, URL of the source, the source does not need to be given a specific article page, just the article list page.
-
per_hours, Scan frequency, in hours, type is integer (1~24 range, we recommend not exceeding once a day, i.e., set to 24)
-
activated, Whether to activate. If turned off, this source will be ignored, and can be turned back on later. Activating and deactivating does not require restarting the Docker container, it will update at the next scheduled task.
6. Local Deployment
As you can see, this project only requires a 7B\9B size LLM and does not require any vector model, which means that just one 3090RTX (24G VRAM) is enough to fully deploy this project locally.
Ensure that your local LLM service is compatible with the openai SDK and configure LLM_API_BASE.
Note: To enable a 7B~9B size LLM to accurately understand tag explanations, it is recommended to use dspy for prompt optimization, but this requires about 50 manually labeled data. See DSPy for details.
🛡️ License Agreement
This project is open source under the Apache2.0.
For commercial and custom cooperation, please contact Email: 35252986@qq.com
Commercial customers, please contact us for registration, the product promises to be forever free.
📬 Contact
For any questions or suggestions, feel free to contact us via issue.
🤝 This project is based on the following excellent open-source projects:
-
GeneralNewsExtractor (General Extractor of News Web Page Body Based on Statistical Learning) https://github.com/GeneralNewsExtractor/GeneralNewsExtractor
-
json_repair (Repair invalid JSON documents) https://github.com/josdejong/jsonrepair/tree/main
-
python-pocketbase (pocketBase client SDK for python) https://github.com/vaphes/pocketbase
Citation
If you reference or cite part or all of this project in your related work, please cite as follows:
Author:Wiseflow Team
https://github.com/TeamWiseFlow/wiseflow
Licensed under Apache2.0